


参考:哈夫曼编码
一、哈夫曼(Huffman)编码
哈夫曼编码是一种十分有效的编码方法,广泛应用于数据压缩中
通过采用不等长的编码方式,根据字符频率的不同,选择不同长度的编码,对频率越高的字符采用越短的编码实现数据的高度压缩。
这种对频率越高的字符采用越短的编码来编码的方式应用的就是贪心算法的思想。
下面看一个例子:
假如我们有一个包含1000个字符的文件,每个字符占1个byte(1byte=8bits),则存储这100个字符一共需要8000bits。这还是有一些大的
那我们统计一下这1000个字符中总共有多少种字符,原来需要8bit来表示一个字符,如果使用更少的位数来表示这些字符,则可以减少存储空间。
假设这1000个字符中总共有a、b、c、d、e、f共6种字符,使用使用3个二进制位来表示的话,存储这1000个字符就只需要3000bits,比原来更节省存储空间。
a(000)、b(001)、c(010)、d(011)、e(100)、f(101)
或许还可以再压缩一下:
根据字符出现的频率给与字符不等长的编码,频率越高的字符编码越短,频率越低的字符编码越长。
它不能像等长编码一样直接按固定长度去读取二进制位,翻译成字符,为了能够准确读取翻译字符,它要求一个字符的编码不能是另外一个字符的前缀。
补充
前缀码: 对每一个字符规定一个0,1串作为其代码,并要求任一字符的代码都不是其他字符代码的前缀。这种编码称为前缀码。
编码的前缀性质可以使译码方法非常简单;例如001011101可以唯一的分解为0,0,101,1101,因而其译码为aabe。
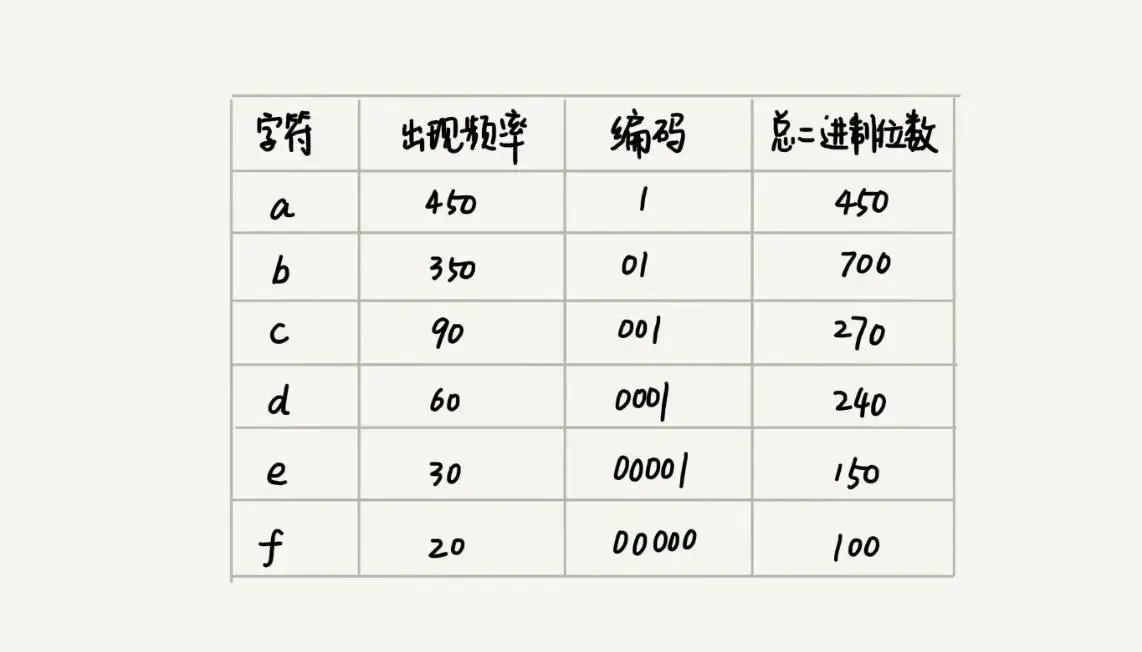
假设a、b、c、d、e、f这6个字符出现的频率依次降低,则我们可以给与他们这样的编码
a(1)、b(01)、c(001)、d(0001)、e(00001)、f(00000)
假如字符的出现频率如图所示,按照这样的编码表示的话,总位数如图,一共2100bits,更加节省空间了
二、实现
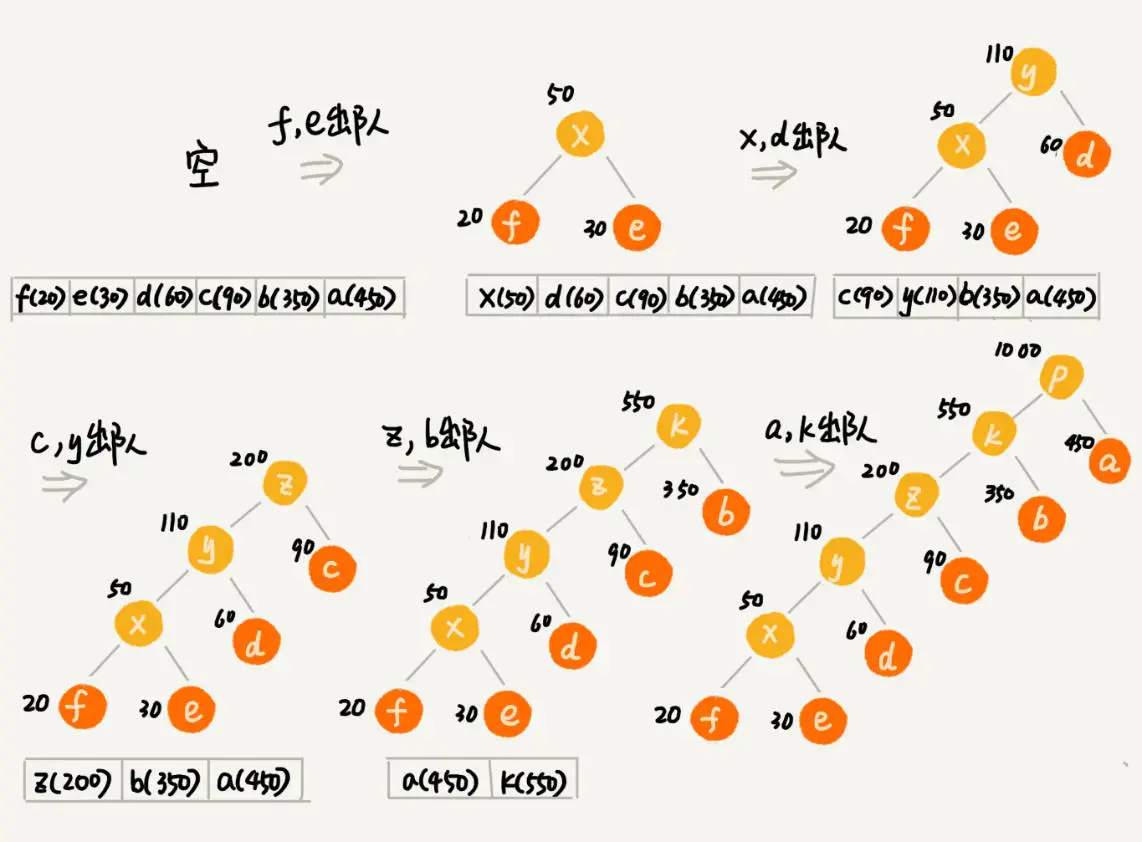
贪心策略:频率小的字符,优先入队。
步骤:
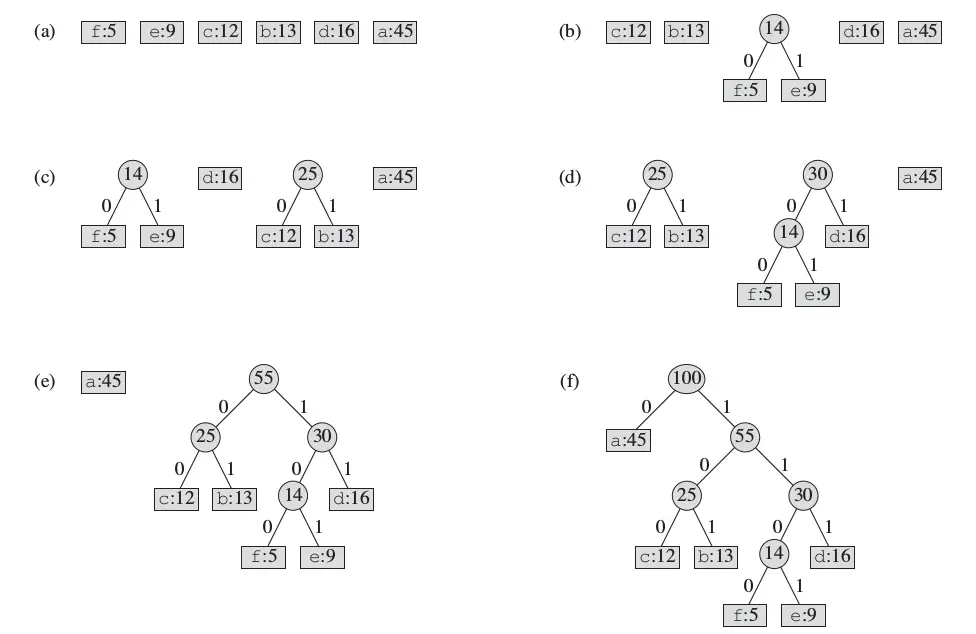
1.将每一个字符作为节点,以出现频率大小作为权重,将其都放入优先队列中(一个最小堆);
2.每次出队两个节点并创建一个父节点,使其权值为刚刚出队的节点的权值和,并且为两个节点的父节点(合并)。然后将这个树入队。
3.重复操作2,直到队列中只有一个元素(此时这个元素表示形式应该为一个树)时,完成创建。
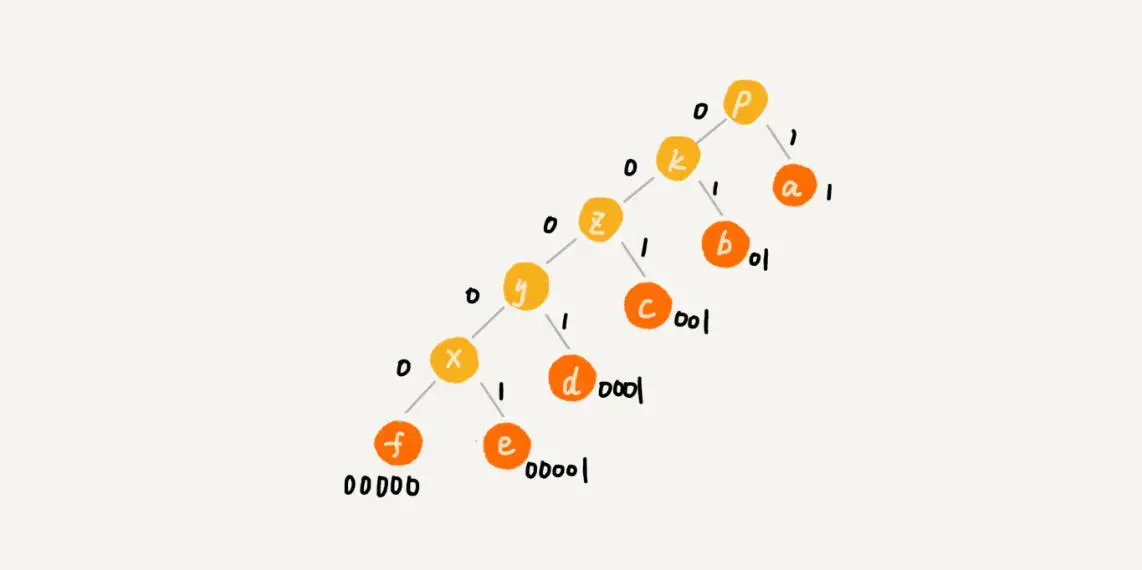
创建好了树,该怎么编码呢?
我们对一个哈夫曼树,从父节点开始的所有节点,往左边标0,右边标1。那么到达叶子节点的顺次编码就可以找到了。
伪代码

C:字符集合
Q:优先队列
EXTRACT-MIN:传入一个队列,出队最小的元素
INSERT:将z插入到Q中
当for循环结束之后,此时队列中只有一个元素,就是我们需要的哈夫曼树,最后返回此树即可。
证明贪婪算法的正确性

假设T树已经是一个最优的树,假设x、y的频率小于等于最低处的a、b,然后交换x、a,y、b。
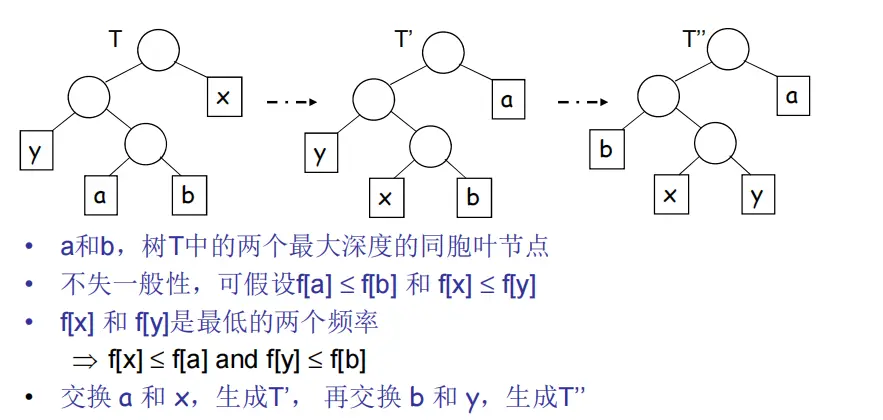
计算代价是否发生变化。
比如这里比较 T 变成 T ’ 后代价是否变化,发现代价变小或不变。
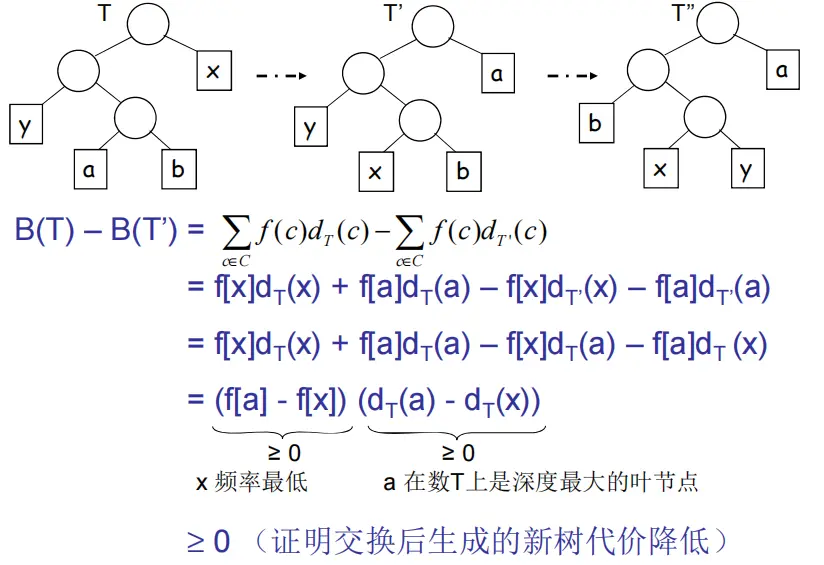
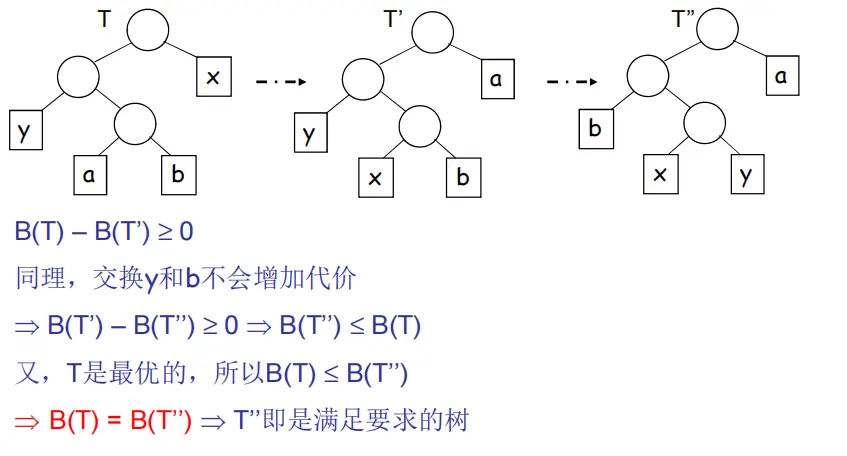
同理T’到T’’,又因为T本来假设就是最优的,所以只能相等
所以T’’也应该符合条件,即贪婪算法,每次取最小的两个节点出来这种做法是正确的
【信息由网络或者个人提供,如有涉及版权请联系COOY资源网邮箱处理】






暂无评论内容