


数据分析是在当今信息爆炸的时代中应用广泛的技术之一。为了从大量的数据中提取有价值的信息,我们需要一种有效的方法来对不同的指标进行权重分配,熵权法可以作为一个客观的综合评价方法,比如根据河流的不同指标,评估不同河流的水质。熵权法能够帮助我们确定不同指标的权重,使得我们能够更准确地评估数据的价值和重要性。本文将介绍熵权法其原理、应用(excel&python)和评估方式。
为什么要用熵权法?或者说具体什么场景下应用。如果你很熟悉业务指标,可以根据你的经验,主观去给指标赋权重,并且指标就几个,这种情况就不需要用熵权法。但是当你不熟悉,无法根据过往经验给权重,那么我们就需要用熵权法。例如,在投资决策中,可以使用熵权法来确定不同投资指标的重要性,从而指导投资策略的制定。接下来我们看什么是熵权法。
一、熵权法的原理
熵是信息理论中表示信息量的概念。熵对不同指标的权重进行分配,指标越混乱熵越大,越有秩序熵越小。那么,熵权法是通过计算每个指标的熵值来衡量其随机性和不确定性,然后根据熵值的大小来确定每个指标的权重,基本思路是根据指标变异性的大小来确定客观权重。总的来说,指标数据变异程度越高,熵越大,给的权重也越高。
二、熵权法的应用
1. 准备数据
①缺失值处理
数据要保证没有缺失值,如果有缺失值,可以考虑用均值,中位数等进行填充。

②确定指标类型
在所有的指标中,可能有正向,可能有负向。正向是数值越大越好,负向是数值越小越好。比如用户分层模型,R最近消费间隔,数值越小越好;F消费频次,M消费金额越大越好。那么R就是负向指标,FM就是正向指标。在本案例数据中p1-P13是正向指标,n1-n2是负向指标。
③数据标准化
确定数据类型,就是在标准化这一步来使用的,标准化是来解决量纲不一致的问题。看到我们的案例数据,最大的单位有百万,最小的是十。我们需要根据公式对正向和负向指标分别标准化。公式如下:
- xij : 对于i个样本,j个指标,则xij为第i个样本的第j个指标;比如这里的x14表示第一个样本的第四个指标数据,也就是为0.3724

2. 实现过程【excel】
①新建辅助行 ,type标记正向指标、负向指标

②计算出每个指标的max,min,max-min

③标准化数据
公式:=IF(type=”p”,(B3-min)/max_min,(max-B3)/max_min)
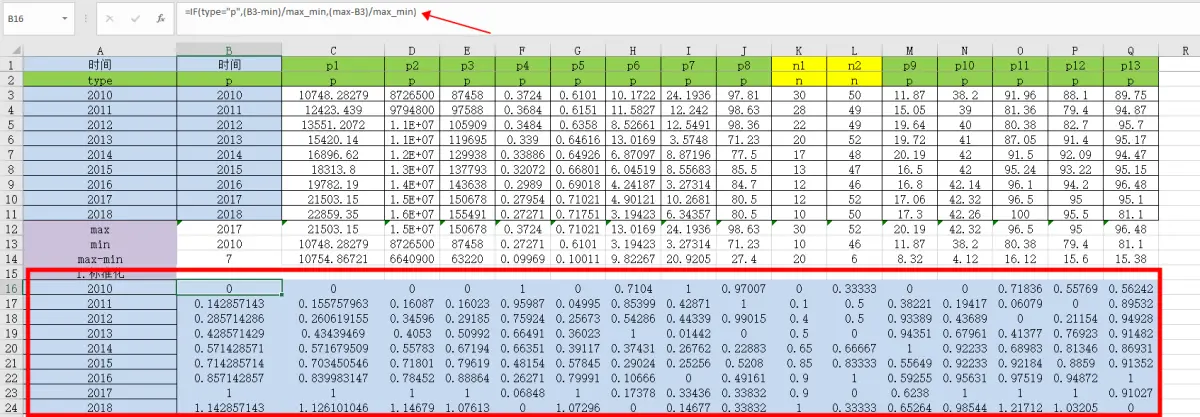
④将值为0的调成0.00001,因为下一步计算熵值时,需要进行log取数,若数值=0,则得出的值就会是无限大,在程序体现就是NaN。为了避免这种情况,若计算结果等于0的情况,则将值稍微调大一点,调成0.00001。
公式:=IF(B16=0,B16+0.00001,B16)
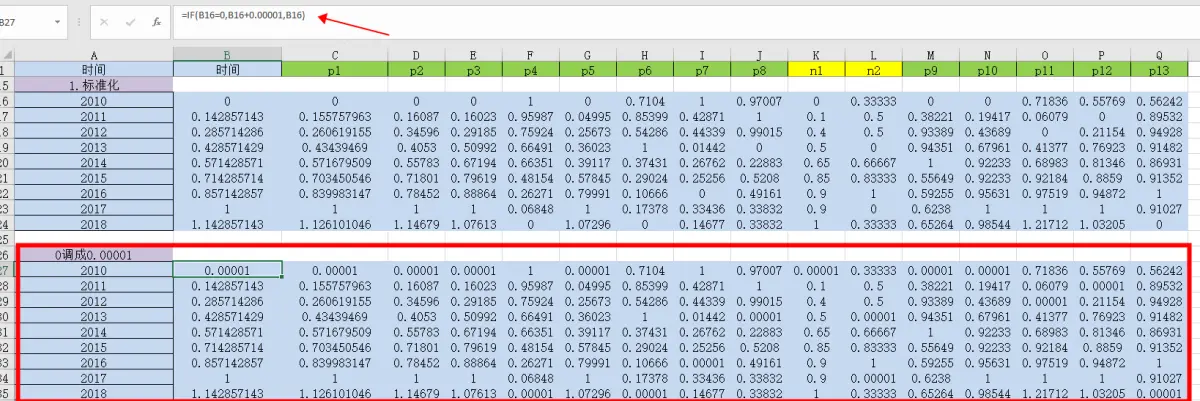
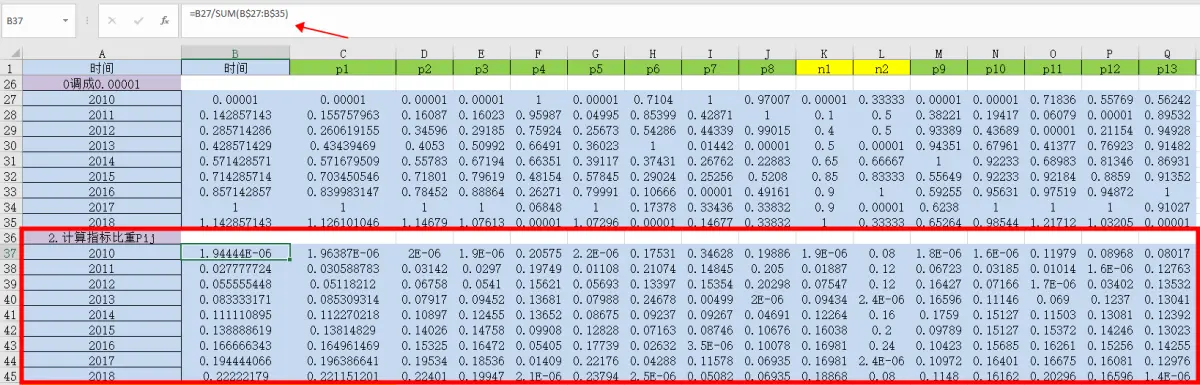
⑤计算指标比重Pij
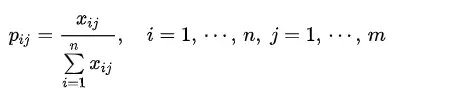
公式:=B27/SUM(B35)
⑥计算熵值
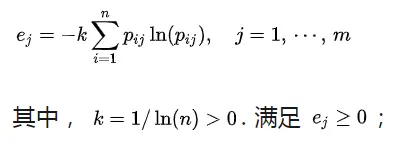
首先计算k,公式:=-1/LN(9),这里因为有9行数据,所以用LN(9)
计算熵值ej,公式:=46*SUMPRODUCT(B37:B45,LN(B37:B45))
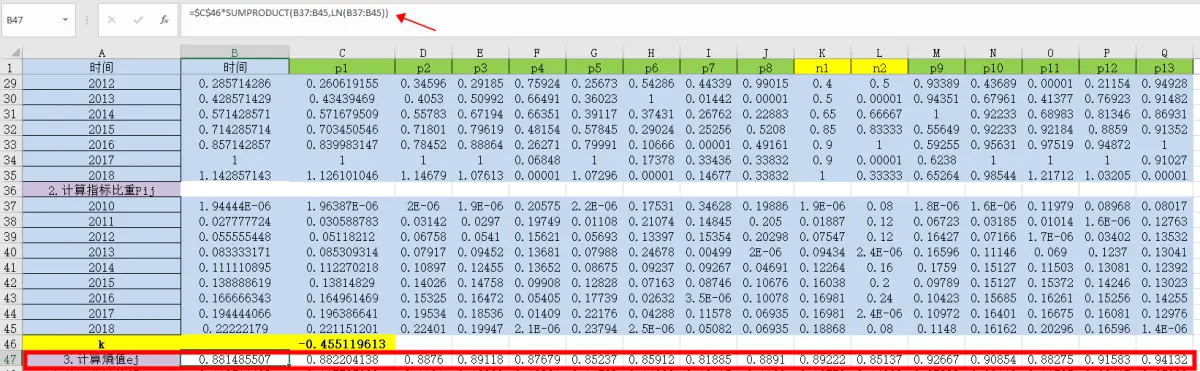
⑦计算变异系数

公式:1-B47
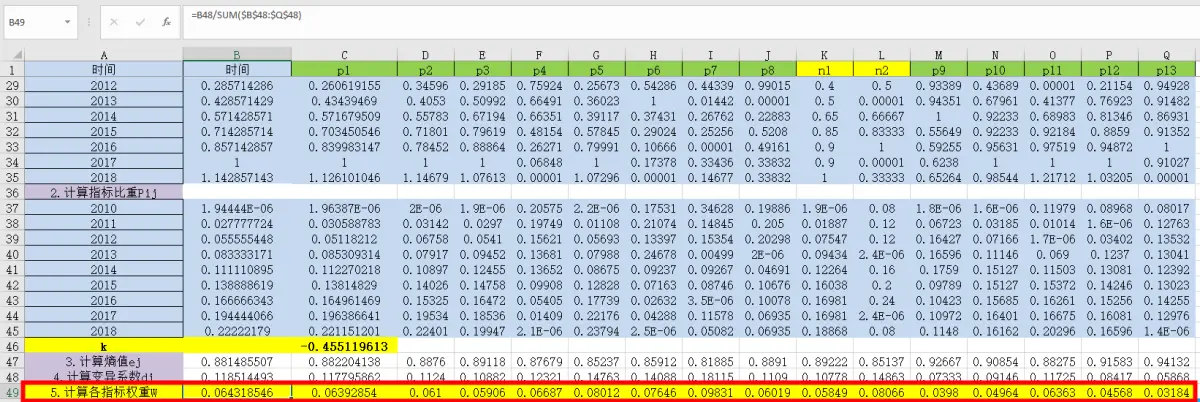
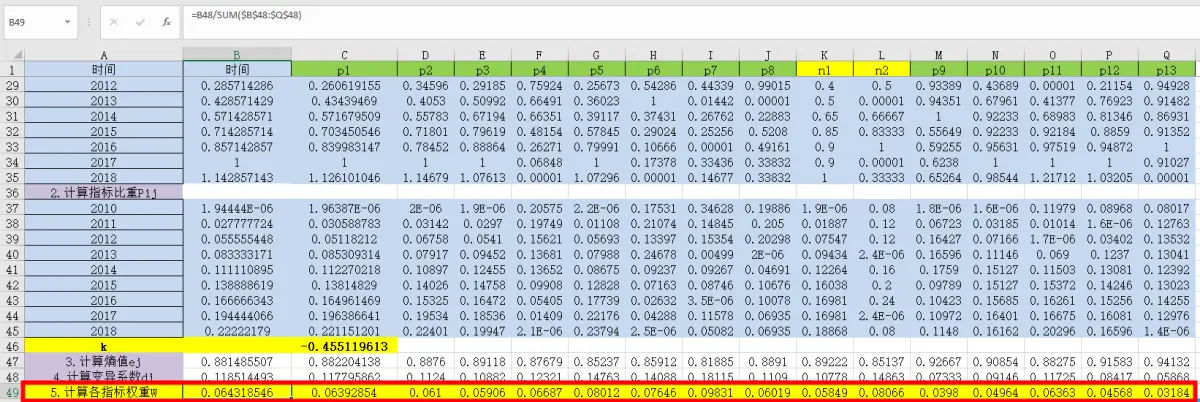
⑧根据变异系数,计算各指标权重
公式:=B48/SUM(48:
48)
⑨线性加权,计算综合得分 xij为标准化之前的数据
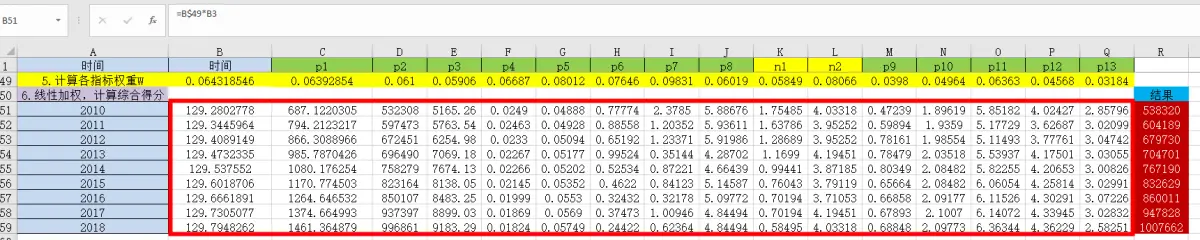
最后将各指标的加权得分相加,计算出综合得分。
3.实现过程【python】
①读取数据
import pandas as pd
import numpy as np
df= pd.read_excel('data_shiyan - 副本.xlsx')
df.head()
②空值处理
df.isnull().sum()
③标准化数据
df = df.set_index(df['时间'])
def data_Standardization(d):
for i in list(d.columns):
Max =np.max(d[i])
Min = np.min(d[i])
if (i=='n1') or (i=='n2'):
d[i] = (Max - d[i]) / (Max - Min)
else:
d[i] = (d[i] - Min) / (Max - Min)
return d
df = data_Standardization(df)
df
④将值为0的调成0.00001,因为下一步计算熵值时,需要进行log取数,若数值=0,则得出的值就会是无限大,在程序体现就是NaN。为了避免这种情况,若计算结果等于0的情况,则将值稍微调大一点,调成0.00001。
df = df.replace(0,0.00001)
⑤计算指标比重Pij
for col in df.columns:
df[col] = df[col] / sum(df[col])
df
⑥计算熵值
k = 1 /np.log(9)
entropy = [(-k) * sum([pij*np.log(pij) for pij in df[col]]) for col in df.columns]
s_entropy = pd.Series(entropy,index=df.columns,name='指标的熵值')
s_entropy
⑦计算变异系数dj
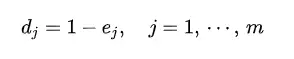
s_by = pd.Series(1-s_entropy,index=df.columns,name='变异系数')
⑧根据变异系数,计算各指标权重
s_weight = s_by/sum(s_by)
s_weight.sort_values(ascending=False)
⑨线性加权,计算综合得分 xij为标准化之前的数据
df_dict ={}
for idx in range(len(df.columns)):
df_dict[df_gz.iloc[:,idx].name] = df_gz.iloc[:,idx] * s_weight[idx]
df_gz['最终得分'] = pd.DataFrame(df_dict).sum(axis=1).round(2)
df_gz.sort_values('最终得分',ascending=False)
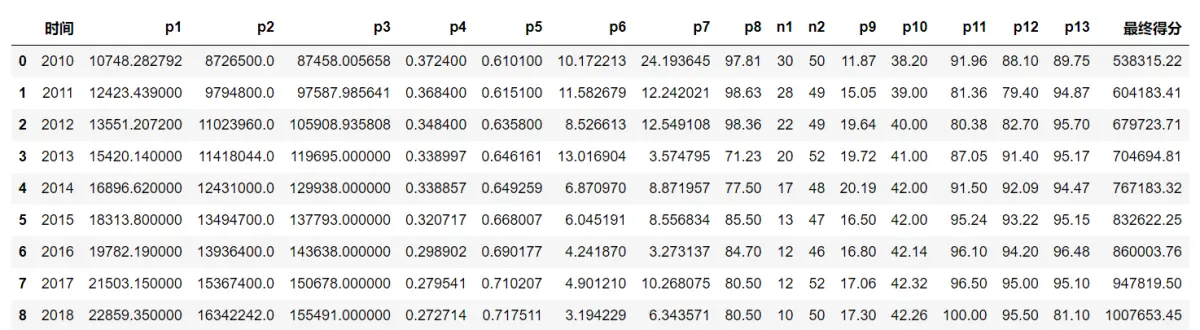
最后将各指标的加权得分相加,计算出综合得分。
4. 得出结论
从各指标权重占比来看,Top3分别是指标p7、n2、p5。2010-2018年期间,综合得分逐年上涨。
三、总结
结语:本文介绍了熵权法作为一种数据分析方法的原理、excel & python 应用和评估方式。通过理解和应用熵权法,我们可以更好地利用数据,做出更准确和可靠的决策。希望本文能对读者对熵权法的理解和运用有所帮助。
【信息由网络或者个人提供,如有涉及版权请联系COOY资源网邮箱处理】




暂无评论内容